Qucit, pour de nouvelles mobilités urbaines (1/2)
L’idée est née d’un coup de malchance urbaine comme il peut nous en arriver régulièrement en tant que citadin utilisant les nouveaux modes de transports en ville. Un beau jour, Raphaël Cherrier s’est retrouvé dans l’incapacité de louer un vélo à Bordeaux, pour la simple et bonne raison qu’à la borne qu’il utilisait régulièrement, ce matin-là, il n’y en avait aucun de disponible !
C’est donc en faisant le constat d’une trop grande difficulté à prévoir ces imprévus, que ce jeune chercheur bordelais a proposé à l’opérateur d’exploiter ses données d’utilisation pour améliorer leur service. Quelques mois après, Qucit se développait. Depuis, cette jeune start-up bordelaise fournit des solutions d’analyse et d’optimisation en temps réel de la mobilité urbaine. Rencontre avec un innovateur urbain.
Pouvez-vous nous en dire un peu plus sur l’innovation urbaine que vous portez au travers de Qucit ?

Raphaël Cherrier : Crédits Qucit
Qucit est une plateforme de modélisation des comportements humains en ville basée sur les data et l’intelligence artificielle. Aujourd’hui cette plateforme est en cours de création. Et un certain nombre de produits destinés à l’analyse de certains types de comportements urbains sont déjà actifs, notamment en ce qui concerne la mobilité.
Nous avons par exemple analysé des flux et réalisé des prédictions sur les Vélib’, sur le temps de recherche de place de stationnement en voirie, sur l’affluence dans les transports en commun et sur la manière dont les piétons vont percevoir l’espace public en fonction des aménagements urbains. Dans ce dernier cas, nous essayons de comprendre quels types de sentiments peuvent être créés par des aménagements urbains différents.
A partir des data qui existent, nous réalisons donc un modèle numérique et complet de la ville. Il s’agit d’abord des data d’infrastructures statiques qui décrivent la ville (position des arbres, des éclairages, des bâtiments et des routes…) A ces data statiques nous ajoutons les data dynamiques (mesures de flux, de position, de bruit…) et en combinant ces deux types de données, nous allons pouvoir prédire différents types de comportements humains en ville à la manière d’une « boule de cristal ».
Comment est née l’idée de Qucit ?
J’étais chercheur aux Arts et Métiers à Bordeaux après une thèse en physique théorique sur les systèmes complexes et les réseaux de neurones et des études à l’Ecole Normale Supérieure de Lyon. L’histoire de Qucit, c’est donc d’abord l’histoire d’un chercheur qui s’ennuie dans son laboratoire, qui utilise régulièrement des Vcub (service de vélos en libre-service mis en place le 20 février 2010 dans la communauté urbaine de Bordeaux — devenue Bordeaux Métropole par la suite) et qui se dit que c’est dommage que l’on puisse concevoir un service générant autant de données, sans être capable de l’équilibrer pour faire en sorte qu’il y ait toujours dans chaque station assez de Vcub et de places disponibles.
Je me suis alors dit que c’était avant tout un problème de logistique pour lequel il faudrait prévoir à l’avance comment les Vélib’ vont se déplacer. Il fallait donc inventer un moyen de définir un système automatisé en utilisant les données disponibles d’une manière plus intelligente. Nous avons commencé à travailler sur cette idée avec Keolis. Et de fil en aiguille, j’ai pris la décision de quitter le monde universitaire pour créer une entreprise qui aurait pour but d’améliorer la mobilité urbaine grâce à l’analyse de données et l’intelligence artificielle. Le premier contrat que l’on a décroché concernait l’utilisation des Vcub à Bordeaux et nous nous sommes ensuite intéressés au stationnement automobile, puis aux transports en commun.
Concrètement comment ça marche ?
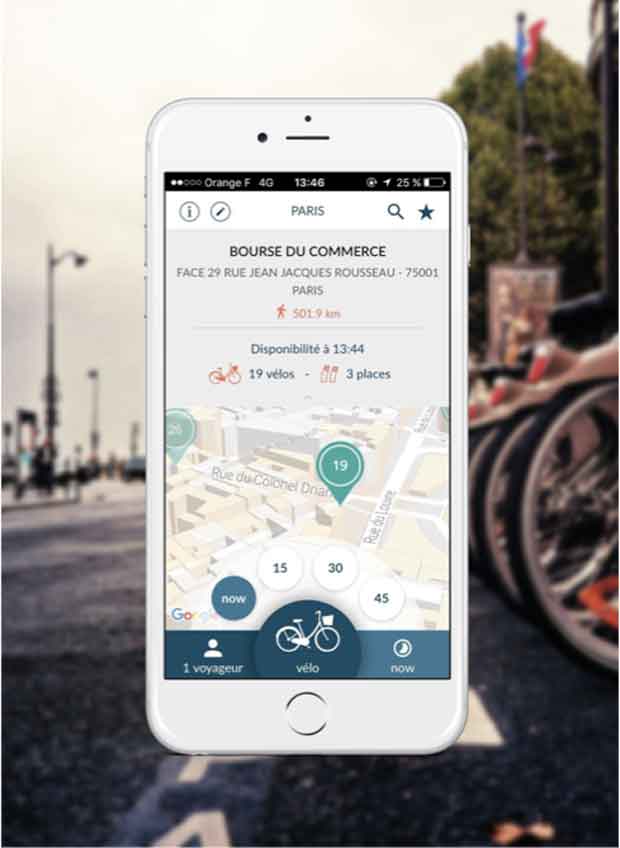
Nous développons des API qui sont des moteurs prédictifs qui viennent s’intégrer dans d’autres types de produits. Si l’on prend un exemple très concret, un calculateur d’itinéraires. Il en existe beaucoup à Paris comme celui du STIF, de la RATP ou de Citymapper. Ces calculateurs d’itinéraires multimodaux permettent de se déplacer d’un point A à un point B en combinant différents modes de transports. En général, ils incluent les transports en commun et la marche à pied. Imaginons maintenant que, sur ce type de calculateur d’itinéraires, vous souhaitiez inclure les Vélib’s pour proposer un premier tronçon en transports en commun puis un deuxième en Vélib’. Il est difficile aujourd’hui de proposer ce type de trajet. En effet, au moment où un utilisateur consulte son itinéraire, il n’est pas possible de savoir si, vingt minutes plus tard, lorsqu’est censé démarrer son deuxième tronçon en Vélib’, il trouvera bien un Vélib’ disponible à la borne ciblée. Il n’est pas non plus possible d’assurer à l’utilisateur qu’à l’arrivée de son trajet en Vélib’, il aura bien une place pour le garer.
Comme les utilisateurs sont habitués à une certaine fiabilité sur les itinéraires proposés, ils ne s’attendent pas à ce qu’on leur propose un trajet pour qu’au final ils ne puissent pas en parcourir l’intégralité. Avec les moteurs prédictifs que nous avons mis au point, il est maintenant possible de garantir jusqu’à plusieurs heures à l’avance à l’utilisateur qu’il trouvera bien un Vélib et une borne disponible. Si le risque est trop fort que ce ne soit pas le cas, le trajet ne lui sera pas proposé.
Nous avons mis au point notre propre application, BikePredict, qui utilise cette technologie et sert à démontrer l’intérêt des applications prédictives pour les vélos en libre-service. Néanmoins, l’API est pensée pour pouvoir être intégrée dans des applications tierces, comme des calculateurs d’itinéraires multimodaux par exemple. Supposons que je sois à Châtelet et que je souhaite me déplacer maintenant jusqu’à la station Jardin du Luxembourg. Actuellement sur l’application Vélib’, il est noté qu’il y a 4 places à la station Jardin du Luxembourg. La question que je me pose est simple : est-ce que dans 20 minutes, une fois arrivé à la station, je retrouverai bien ces 4 places ? Ou, au contraire, vais-je devoir tourner en rond pour trouver une autre station que celle visée au départ ? Il s’agit de faire en sorte que mon trajet soit le plus court mais aussi le plus sûr, car je n’ai aucune envie de me préoccuper pendant tout le trajet de savoir si je vais en effet trouver une place à mon arrivée ou pas.
Dans la dernière version de l’application Bike Predict que nous avons lancée, le trajet proposé sera donc le plus court mais aussi le plus sûr, en fonction de la disponibilité de Vélib’ au départ et d’un taux suffisamment fort de places disponibles à votre arrivée à destination. Pour nous, la prochaine étape est de combiner notre API avec d’autres applications de calculateurs d’itinéraires qui prennent en compte d’autres types de transports. C’est ce sur quoi nous travaillons avec un autre partenaire.
Pouvez-vous nous expliquer la manière dont fonctionnent ces API ?
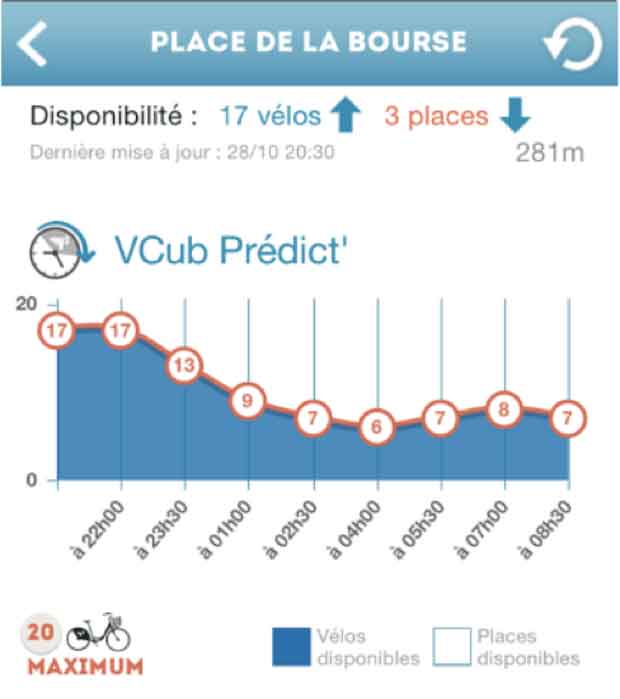
Aujourd’hui, en temps réel, nous pouvons d’ores et déjà savoir combien de vélos sont disponibles dans une station et combien on y trouve de places disponibles. Cette information nous est fournie par les bornes elles-mêmes. En plus de cela, depuis trois ans, nous stockons l’historique de toutes les données de Vélib’. Ce qui signifie que, minute par minute, nous avons en notre possession tout l’historique de l’utilisation des Vélib’ pour chaque station. Cela nous permet donc de constituer des modèles qui vont eux, être basés sur différents critères : le calendrier (est-ce un jour férié, une période de vacances scolaires…), la météo (est-ce qu’il fait chaud, est-ce qu’il pleut, etc.), l’état en temps réel du système (combien y a-t-il de vélos dans la station et dans les stations avoisinantes et quelle a été l’activité des dernières heures pour essayer de comprendre les différents flux en train de se mettre en place). A partir de là, nous allons pouvoir prédire jusqu’à 45 minutes à l’avance (même si nous pouvons prédire jusqu’à 12h, au-delà de 45 minutes, la prédiction s’avère inutile) si à telle ou telle station vous allez retrouver un Vélib’ ou une place disponible.
L’historique nous sert donc à calibrer des modèles qui, au final, vont être uniquement basés sur des données contextuelles. Ces modèles vont se référer au jour, à l’heure, aux vacances scolaires, au temps qu’il fait, à l’état en temps réel du système. Le modèle historique est en réalité un cas particulier et très simplifié des modèles numériques que nous produisons. Il est donc très simple : je prends trois ans de données sur l’utilisation des Vélib’. Je peux définir à partir des données historiques que le lundi matin à 9h, il y a tant de Vélib’ sur cette station et à 10H il y a tant de Vélib’.
A cela je peux ajouter quelque chose de plus subtil : prenons le même exemple, nous sommes lundi matin et il est 9h. Comme j’ai accès aux données en temps réel, je veux savoir combien il aura de Vélib’ le même jour à 10h. Je regarde donc l’historique et je me rends compte que le lundi matin entre 9h et 10h, la station récupère 4 Vélib’. J’en déduis donc qu’à 10h, il y aura 4 Vélib’ de plus qu’à 9h sur la même station. Ca c’est un modèle historique simple qui prend en compte deux variables : le jour de la semaine et l’horaire.
Au final, notre modèle est celui-ci, sauf que nous y ajoutons beaucoup plus de variables. Lundi, 9h du matin, nous sommes hors vacances scolaires, ce n’est pas un jour férié, la température est de tel niveau, la pluie est de tel niveau, la direction du vent est de tel niveau, etc. Rien que pour les variables de météo, nous en ajoutons 80. A cela, nous ajoutons également l’état du dispositif concernant les stations voisines et potentiellement de l’information concernant tous les évènements spéciaux…
Et si un syndicat décide d’organiser une manifestation dans trois jours dans une partie de la ville ? Cette donnée est-elle aussi modélisable ?
Oui tout à fait, si nous avons accès aux data correspondantes ! Il faudrait pour cela que nous puissions nous connecter à un flux de données fournissant le tracé de la manifestation. Avec suffisamment d’historique de manifestations nous pourrions alors entraîner nos modèles contextuels à apprendre par eux-mêmes en quoi une manifestation qui passe par tel endroit impactera la station de métro ou de Vélib’ avoisinante. Ensuite l’algorithme pourra prédire l’impact d’une manifestation en fonction des données récupérées en temps réel.
C’est ce qu’on appelle de l’apprentissage machine : il s’agit de mettre l’algorithme en présence de différentes variables d’entrées et de leur impact sur ce qu’on cherche à prédire. De la même manière qu’un humain fait son apprentissage, les algorithmes vont apprendre mais de manière beaucoup plus rigoureuse, en traitant une énorme quantité de données. Nous sommes en présence d’algorithmes ultra sophistiqués que nous utilisons pour différentes applications. Que ce soit prédire l’état d’une station de Vélib’, le temps de recherche d’une place de stationnement ou d’autres quantités liées à la mobilité urbaine ou aux comportements humains.
Retrouvez la suite de cette interview sur le blog Demain la Ville dès demain.